这篇其实跟使用MXnet的关系不大,但对于我们理解深度学习的框架设计还是很有帮助的。
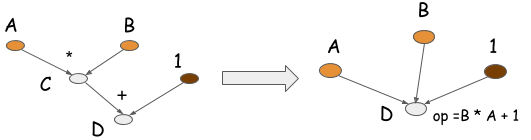
首先还是对promgramming models的一个简单介绍,这个东西实际上是在编译里面经常出现的东西,我们在编译我们的程序的时候,可以对变量构建出一个计算图,然后可以对这个图进行相应的优化来提高速度或者节省内存。到了DL框架上,这些用处就更加重要了,但是也不是所有的DL框架都有计算图的,因为这其中存在一个research和engineering的权衡。计算图的简单理解就是下图:
一、Symbolic vs. Imperative Programs
首先要说的就是符号式程序和命令式程序等区别了,类似于程序语言设计中的区别,能否在程序代码执行的过程中,能否方便直接的进行修改、分支选择或者循环以及得到中间的输出结果等操作,是区分符号式和命令式的关键,当然这些只是我个人的直观理解。。。。稍微正式点就是:Most symbolic-style programs contain, either explicitly or implicitly, a compile step. This converts the computation graph into a function that can be called. Computation occurs in the last step in the code. The major characteristic of symbolic programs is the clear separation between defining the computation graph and compiling.然后imperative就是你怎么写它怎么跑,你什么时候写好了让他跑,他就什么时候开始跑。
符号式的设计方法有很多好处,tenserflow和MXnet都是基于这种方法编写的,首先因为它们都可以构建出计算图,这样以来就可以对计算图进行优化,通过dependency的分析等等,可以大大的提高算法训练的速度和减少内存的需要,甚至于TQ最新的那篇paper,通过手动置顶一些mirror来保存forward的时候的部分feature map而不是全部,最终resnet152训练要求的48G显存降到了6G,而且速度上并没有掉太多(我个人实际使用的时候,可能是因为miroor设置的不好,降了很多速度。。),但是符号式的缺点也很明显,它给使用者的权限太少了,因为算法在训练的时候,是在定义好的symbil的基础上进行自己的优化,然后传入data开始训练,然后你想在里面做一些奇葩的操作例如循环,if之类的,基本是不可能的。。
所以在我们做research的时候,专注点在于算法的性能而不是效率低时候,可能torch和chaniner这种 imperative-style program是个不错的选择,在torch框架上,你可以很容易的做出一些mxnet很难进行的动作,但是因为我个人暂时也不是很熟悉它们,而且我们的重点还是mxnet,所以我也不强行讲了。下面是一个简单的例子,我们在imperative program可以容易的写出来,但是在符号式的却很难。
a = 2 b = a + 1 d = np.zeros(10) for i in range(d): d += np.zeros(10)
二、粗细力度,自动求导
框架的粗粒度、细粒度和自动求导的概念之前听过很多次了,前两者以前是完全不懂并且觉得很高端,后者是以为是字面意思然后觉得太可怕。。。实际上粗细粒度是对框架提供的一个操作大小的描述,粗粒度操作如:FC,BN,细粒度操作如:elemenwise的sum、mul之类的。
还是拿Tenserflow和MXnet来说,前者提供了很多的底层小操作,所以它是一个细粒度的框架,这样的好处是,使用者要想定义自己的操作的时候,就可以通过组合tenserflow里面的op来实现,大大的减小了难度,但这样带来的坏处就是,最终的计算图会又大又复杂,很难去优化。这也是google背书的Tenserflow之前在性能上反而不是MXnet的原因之一的吧。 MXnet我们就很熟悉它的那些OP了,基本上都是一些粗粒度的操作,这样我们在定义自己的OP的时候,只能去默默的写C++代码,个中滋味,就不多说了。。。粗粒度的操作带来的好处当然就是性能的提升。
自动求导这个概念,简单的理解就是,框架给你提高的OP,你只要用他们做fwd,然后backward会自动定义好,因为这些OP的BP已经有人写好了,并且整个BP的流程也可以推到出来然后建立好。并不是你在定义自己的操作的时候,代码能自动帮你写这个操作的BP。
总结
我发现做系统设计这些真的很interesting,要不是我的代码水平太弱鸡,真是分分钟钟想去搞系统啊。。